



I set myself a small challenge to be able to transcribe the audio from a list of supplied YouTube videos and then be able to query the transcriptions.
The architecture is as follows:
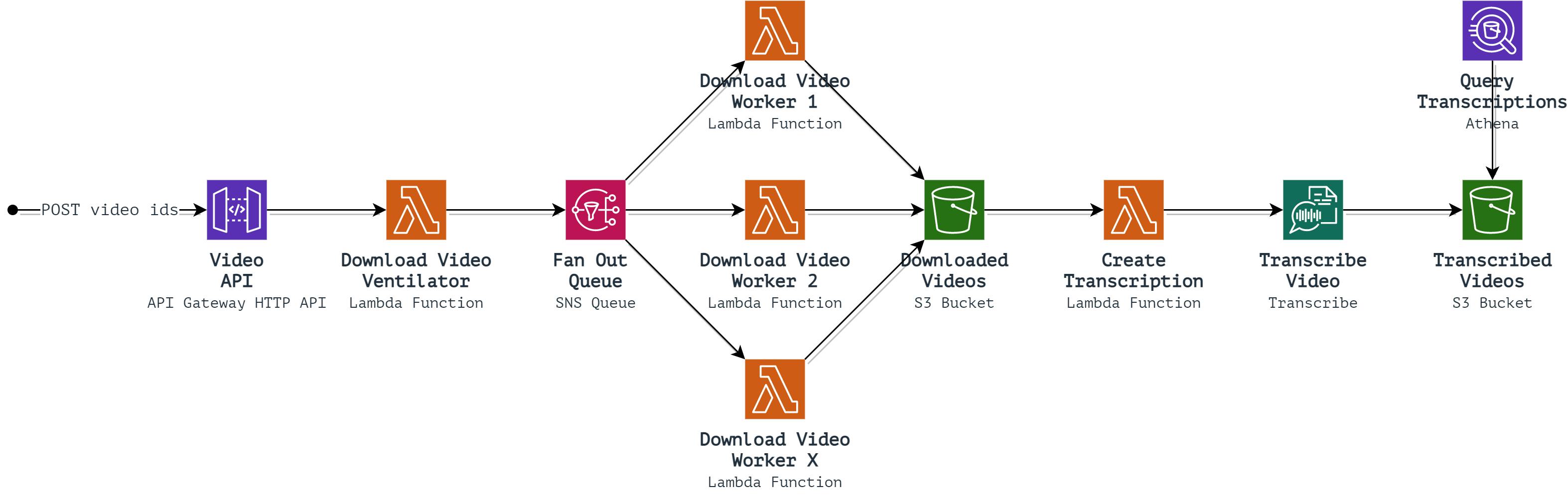 Services: API Gateway HTTP API, TypeScript Lambda Functions, SNS, S3, Transcribe, Athena
Services: API Gateway HTTP API, TypeScript Lambda Functions, SNS, S3, Transcribe, Athena
The expected outcome is to be able to query Athena for a count of how many times a word is spoken in a video:

Video API
CDK is used to create an APIGateway HTTP API.
const httpApi = new HttpApi(this, 'video-api');
httpApi.addRoutes({
path: '/transcription',
methods: [ HttpMethod.POST ],
integration: new LambdaProxyIntegration({
handler: downloadVideoVentilatorFunction
})
});
A POST to /transcription with an array of YouTube video ids will respond with a will integrate with the download video ventilator lambda function.
{
"videoIds": [
"h1pLVA-Z6NU",
"6RePylO53tg",
"L1PWanBjc-A"
]
}
Download Video Ventilator Lambda Function
The lambda function takes the array of video ids from the api request and for each one sends a message to an SNS topic. The message solely consists of the video id. SNS is used to fan out each message so that each video can be processed in parallel.
import { APIGatewayProxyEvent, APIGatewayProxyResult } from 'aws-lambda';
import { SNS } from '@aws-sdk/client-sns';
const snsClient = new SNS({});
export async function handler (event: APIGatewayProxyEvent): Promise<APIGatewayProxyResult> {
const body = JSON.parse(event.body as string);
const videoIds: string[] = body.videoIds;
const publishMessageTasks = videoIds.map(videoId => {
return snsClient.publish({
Message: videoId,
MessageStructure: 'string',
TopicArn: process.env.TopicArn});
});
await Promise.all(publishMessageTasks);
return { 'statusCode': 202, 'body': '' };
};
CDK is used to create the lambda function and SNS topic. Permission is granted to allow the function to publish a message to the SNS topic.
const snsTopic = new Topic(this, 'transcription-requested');
const downloadVideoVentilatorFunction = new NodejsFunction(this, 'download-video-ventilator', {
runtime: Runtime.NODEJS_12_X,
entry: 'handlers/download-video-ventilator/index.ts',
handler: 'handler',
environment: {
TopicArn: snsTopic.topicArn
},
});
snsTopic.grantPublish(downloadVideoVentilatorFunction);
Download Video Worker Lambda Function
The lambda function subscribes to the SNS topic, takes the video id in the message and uses the ytdl-core library to download the YouTube audio. It streams the result into the transcribed videos S3 bucket.
import { S3 } from '@aws-sdk/client-s3';
import { SNSEvent } from 'aws-lambda';
import { Stream } from 'stream';
import { Upload } from '@aws-sdk/lib-storage';
import ytdl from 'ytdl-core';
const s3Client = new S3({});
export async function handler (event: SNSEvent): Promise<void> {
const videoId = event.Records[0].Sns.Message;
const videoUrl = `https://www.youtube.com/watch?v=${videoId}`;
const videoExtension = 'webm';
const videoFileName = `${videoId}.${videoExtension}`;
console.log(`Downloading video ${videoUrl}`);
const passThrough = new Stream.PassThrough();
ytdl(videoUrl, { filter: 'audioonly', quality: 'lowestaudio' }).pipe(passThrough);
const uploader = new Upload({
client: s3Client,
params: {
Bucket: process.env.BUCKET_NAME,
Key: videoFileName,
Body: passThrough
}
});
uploader.on('httpUploadProgress', progress => console.log(progress));
await uploader.done();
};
CDK is used to create the lambda function that subscribes to the SNS topic. The timeout and memory size need to be increased in order to successfully download the video. Permission is granted to allow the function to write to the downloaded videos S3 bucket.
const downloadVideoWorkerFunction = new NodejsFunction(this, 'download-video-worker', {
runtime: Runtime.NODEJS_12_X,
entry: 'handlers/download-video-worker/index.ts',
handler: 'handler',
environment: {
BUCKET_NAME: downloadedVideosBucket.bucketName
},
timeout: Duration.minutes(2),
memorySize: 512
});
downloadedVideosBucket.grantWrite(downloadVideoWorkerFunction);
snsTopic.addSubscription(new LambdaSubscription(downloadVideoWorkerFunction));
Create Transcription Lambda Function
The lambda function subscribes to the Video Store S3 bucket object created event. When a video is created in the bucket, the lambda function will create an Amazon Transcribe job.
import { S3Event } from 'aws-lambda';
import { Transcribe } from '@aws-sdk/client-transcribe';
const transcribeClient = new Transcribe({});
export async function handler (event: S3Event): Promise<void> {
const s3 = event.Records[0].s3;
const s3BucketName = s3.bucket.name;
const videoFileName = s3.object.key;
const job = await transcribeClient.startTranscriptionJob({
LanguageCode: 'en-GB',
Media: {
MediaFileUri: `s3://${s3BucketName}/${videoFileName}`
},
MediaFormat: 'webm',
TranscriptionJobName: videoFileName,
OutputBucketName: process.env.BUCKET_NAME
});
console.log(JSON.stringify(job.TranscriptionJob));
};
CDK is used to create the lambda function, S3 bucket notification and permissions for the lambda function to read the downloaded videos S3 bucket and to create a transcription job.
const createTranscriptionFunction = new NodejsFunction(this, 'create-transcription', {
runtime: Runtime.NODEJS_12_X,
entry: 'handlers/create-transcription/index.ts',
handler: 'handler',
environment: {
BUCKET_NAME: transcribedVideosBucket.bucketName
},
});
const startTranscriptionJobPolicy = new PolicyStatement({
effect: Effect.ALLOW,
resources: ['*'],
actions: ['transcribe:StartTranscriptionJob']
});
createTranscriptionFunction.addToRolePolicy(startTranscriptionJobPolicy);
downloadedVideosBucket.grantRead(createTranscriptionFunction)
downloadedVideosBucket.addObjectCreatedNotification(
new LambdaDestination(createTranscriptionFunction)
);
transcribedVideosBucket.grantWrite(createTranscriptionFunction);
Athena
This is the first time I've used Athena. From a CDK point of view, the best I could come up with in the time I had was to create two Athena queries that can be run. The first one will create an Athena database named videos.
const databaseName = 'videos';
new CfnNamedQuery(this, 'database', {
database: databaseName,
queryString: `CREATE DATABASE IF NOT EXISTS \`${databaseName}\`;`
});
The second one will create a table named transcriptions based on the structure of the data saved in the transcribed videosS3 bucket.
new CfnNamedQuery(this, 'table', {
database: databaseName,
queryString: `
CREATE EXTERNAL TABLE IF NOT EXISTS ${databaseName}.transcriptions (
jobName string,
results struct<transcripts: array<struct<transcript: string>>,
items: array<struct<start_time: string, end_time: string,
alternatives: array<struct<content: string>>>>>
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1'
)
LOCATION 's3://${transcribedVideosBucket.bucketName}/'
TBLPROPERTIES ('has_encrypted_data'='false');
`
});
The table can then be queried.
select
jobName,
count(items.alternatives[1].content) as count
from transcriptions
cross join unnest(results.items) as t(items)
where lower(items.alternatives[1].content) = 'a-word'
group by jobName
order by count desc
